The highest-fit use cases span both cross-functional teams and industry-specific workflows. From Support, IT, Sales, Compliance, and Engineering to sectors like financial services, healthcare, e-commerce, and professional services—these are the environments where accurate answers, governed automation, and reliable AI reasoning create outsized impact.
rag as a service
RAG as a Service
Reliable, access-true answers from your private knowledge—delivered as a enterprise-ready
agent that we build, integrate, and maintain!
RAG AS A SERVICE
What is INFINARA GLOBAL's RAG as a Service and who’s it for?
Our RaaS is an enterprise-grade approach to retrieval-augmented generation where INFINARA GLOBAL provides the service and the software: we onboard your data sources, configure AI models, guardrails and AI systems, and deliver a generative AI agent that respects your access controls and works with your existing systems. It’s a pragmatic path to enterprise AI—without the do it yourself approach.


RAG as a Service helps teams deliver more accurate answers, better customer experiences, and smoother operations by grounding AI in your approved data, policies, and security standards. It combines retrieval, NLP, and machine learning to power real enterprise workflows, enabling you to roll out trustworthy AI across functions quickly and safely.
RAG as a Service is useful for Financial services (KYC, fraud detection, policies), Healthcare (SOPs, image and video analysis, PHI controls), E-commerce (catalog Q&A, returns), Professional services (knowledge capture for global organizations) and really any organization that’s trying gain more from its data.
who uses it
High-fit teams & use cases

Sales Enablement
Knowledge search, L1 deflection, policy Q&A; virtual assistants that surface
relevant data with citations.

Support & Success
Competitive intel, product FAQs, proposal assist; understanding customer preferences and
personalize customer interactions.

Compliance & Legal
Access-true answers with citations; risk management and audit trails.

Engineering Productivity
Repo/wiki retrieval, SOPs; data analysis patterns for data scientists.
our process
How it works
Stage 0
We scope your pilot & onboarding plan
A 30–45 minute demo + discovery with your stakeholders (Support, IT, Security, Compliance) to understand goals, success metrics, priority use cases, data sources, identity/ACL model (SSO/SAML), deployment preference (SaaS/Private/VPC), and any compliance constraints.

Stage 0.5
Onboarding Proposal
Within 1–2 business days we share a short plan—proposed architecture, timeline, acceptance criteria—and a one-time onboarding cost (fixed fee) based on scope (connectors, volume, ACL complexity, evaluations). Managed subscription is quoted separately.

Stage 1
We onboard your sources
We connect data sources (Google Drive, SharePoint, Confluence, Notion, S3/GCS, Jira, Zendesk, Salesforce, databases), map ACLs, and plan AI integration to your technology stack.

Stage 2
We ingest & enrich your content
We parse PDFs, slides, tables, and images; run OCR; version and deduplicate; and capture training data signals from feedback and raw data.

Stage 3
We index & optimize for your queries
Hybrid semantic + keyword search, smart chunking, metadata filters, freshness pipelines—tuned for your terminology and AI platform preferences.

Stage 4
We ground generation & enforce policies
Cross-encoder reranking, citations, policy filters, guardrails—and optional fine tuning. Works with large language models, machine learning models, and custom AI models.

Stage 5
We evaluate, tune & maintain performance
Eval sets, feedback loops, drift detection, monthly tuning cycles, and QBRs—so quality improves over time and supports your digital transformation.

Stage 6
We deploy and transition to a managed subscription
Production rollout (SaaS, Private, or VPC-isolated) with SSO/SAML, RBAC, logging, and monitoring. Ongoing support and maintenance include regression triage, retrieval and prompt/reranker updates, content hygiene playbooks, and SLAs. We proactively track benchmarks and keep the system current with state-of-the-art practices (model/retrieval upgrades, safety/evaluation improvements, and cost/perf optimizations), and expand to new use cases as your needs grow.
capabilities
Engineered for accuracy

Multimodal retrieval
Docs, tables, images, and transcripts—all retrievable with citations via natural
language.

Access-true answers
Honors source ACLs and row-level permissions end-to-end across AI systems.

Observability
Retrieval hit rate, context quality, and answer quality dashboards—evidence for
enterprise AI governance.

Freshness & sync
Near real-time updates; change-event reindexing for living knowledge and active AI
enterprise use.

Agent-ready
AI agents and virtual assistants with safe function calling (tickets, CRM notes,
knowledge updates).
reference architecture
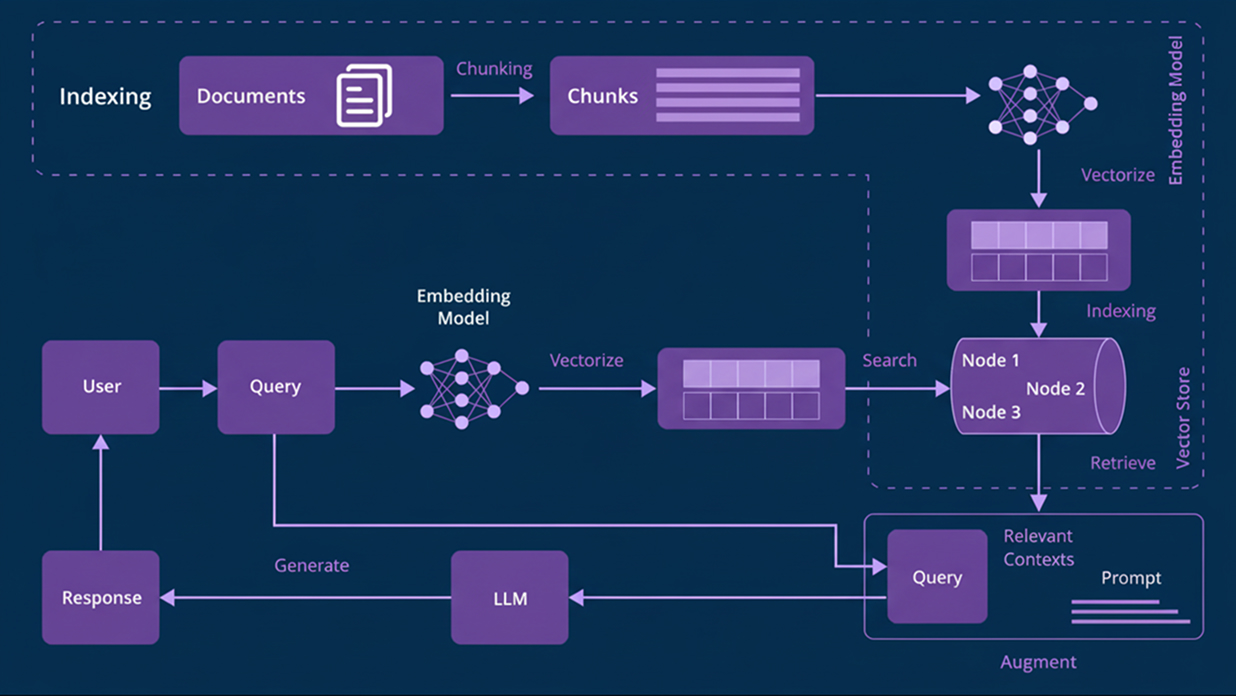
Deployment options
- SaaS and Private cloud
- VPC-isolated deployments for regulated teams (keep data in-tenant and align with enterprise artificial intelligence controls).
what you get
Delivered, production-ready enterprise AI
Production-ready agent tailored to your use case (support, search, enablement, compliance)—ready for real business processes across various business functions.
Source connectors configured and synced; data governance and ACL mapping across AI systems and content.
Eval harness & dashboards with baselines and SLAs; drift detection & monthly tuning to optimize resource allocation and boost productivity.
Playbooks for content hygiene, updates, ownership, and AI implementation best practices.
Ongoing maintenance—retrieval fixes, prompts/rerankers, regressions triage; follow-through on AI adoption and market trends.
frequently asked questions
FAQs
How is this different from generic chatbots or other enterprise AI tools?
We deliver the working agent, not just tooling—plus onboarding, evaluations, drift fixes,
and monthly tuning on your chosen AI platform.
Can you deploy in our VPC and preserve our ACLs?
Yes. We support VPC-isolated deployments and preserve source ACLs end-to-end for access-true
answers across AI systems.
What evaluation metrics do you expose?
Retrieval hit rate, context quality, and answer quality dashboards with baselines and target
SLAs—evidence for enterprise AI governance.
What models and vector stores do you support?
Open/closed LLMs, large language models, machine learning models, pgvector,
OpenSearch/Elastic, Pinecone—selected to match your constraints.
How fast to first value?
Guided pilot to production in weeks, followed by managed improvements—accelerating AI
adoption across teams.